Data Mining in Python
Preface
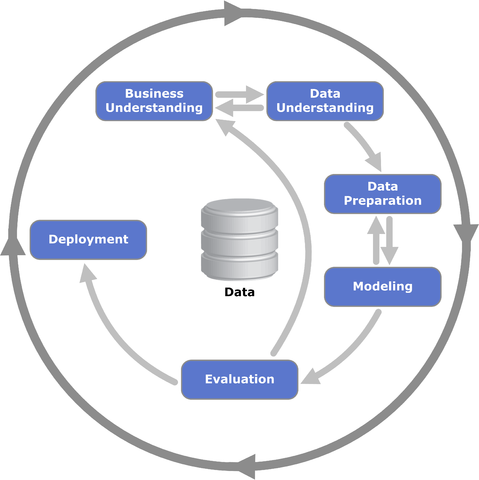
Data mining is the process of sorting through large datasets to identify patterns or relationships to inform business decisions. It is a crucial aspect of modern data analytics, particularly for industries that rely heavily on large amounts of data to inform their business operations.
Prerequisites
Before starting this module make sure you have:
access to the book Nield, T. (2022). Essential Math for Data Science. O’Reilly Media, Inc.
a data science environment setup
Purpose of this course
The general learning outcome of this course is:
The student is able to perform a well-defined task independently in a relatively clearly arranged situation, or is able to perform in a complex and unpredictable situation under supervision.
The course will provide you with a few essential data mining skills. The focus will lie on non-linear modeling techniques - k-Nearest Neighbors (kNN) and Naive Bayes classification.
After a successful completion of the course, a student can demonstrate his or her ability to:
- explore and prepare data for a given non-linear model
- train en test a non-linear model
- evaluate the quality of a trained model
Structure of the course
| Week nr. | Module name | Readings |
|---|---|---|
| 2 | Onboarding and Data Exploration | |
| 3-4 | Lazy Learning with kNN | Nield Ch.1 up to and including ‘Exponents’ |
| 5-6 | Probabilistic Learning with Naive Bayes Classification | Nield Ch.2 up to and including ‘Probablity Math’, Ch.3, Ch.4 up to and including ‘What Is a Vector?’ |
| 7 | Project Application |
Through the whole of the program you’ll be working on your own data mining projects:
You will setup your own data science environment
Find and choose datasets for your projects
Run several full data mining cycles
Document and share your learnings
Demonstrate you newly acquired competences and skills
Make sure all steps in the data mining process are properly documented. The quality of documentation must be such that an informed data specialist must be able to understand the challenge and the conclusions, the design decisions and the reasons for the choices made during the process.
Stretch and Challenge: Advanced students can further research and explore new algorithms for data mining, comparing their performance with KNN and Naive Bayes.
Inclusion: Students who are struggling can work with a partner or teacher during activities to ensure they comprehend the material.
Essential Math
For k-Nearest Neighbors
An essential element of the k-Nearest Neighbor model is distance. Several methods exist to calculate the distance between two points. One is the Euclidean distance. Let point \(p\) have Cartesian coordinates \((p_1,p_2)\) and let point \(q\) have coordinates \((q_1,q_2)\). Then the distance between \(p\) and \(q\) is given by:
\[ d(p,q) = \sqrt{\sum_{i=1}^2{(p_i-q_i)^2}} \]
For higher dimensions \(n\) this becomes:
\[ d(p,q) = \sqrt{\sum_{i=1}^n{(p_i-q_i)^2}} \]
Important math topics:
Order of operation: deduct or square first?
Variables and types: what are the variables in the above formulas and of what type are they?
Functions: which are the dependent and which the independent variables?
Summations: what is the value of \(\sum_{i=3}^4{(i^2)}\)
Exponents: what is the value of \((\sum_{i=3}^4{(i^2)})^{-\frac{1}{2}}\)
For Naive Bayes
Probability math
Descriptive statistics
Vectors
About the author

Witek ten Hove is a senior instructor and researcher at HAN University of Applied Sciences. His main areas of expertise are Data en Web Technologies.
Through his extensive business experience in Finance and International Trade and thorough knowledge of modern data technologies, he is able to make connections between technology and business. As an open source evangelist he firmly believe in the power of knowledge sharing. His mission is to inspire business professionals and help them exploit the full potential of smart technologies.
He is the owner of Ten Hove Business Data Solutions, a consultancy and training company helping organizations to achieve maximum business value through data driven solutions.